Perception Infrastructure¶
In the B-Human context when we say Perception we mean image processing. The robots other sensors like IMU, joint angles and contact sensors and handled independently.
The perception modules run in the context of the threads Lower and Upper, depending on the used camera. They detect features in the image that was just taken by the camera and can be separated into four categories. The modules of the perception infrastructure provide representations that deal with the perspective of the image taken, provide the image in different formats, and provide representations that limit the area interesting for further image processing steps. Based on these representations, modules detect features useful for self-localization, the ball, and other robots.
NAO Cameras¶
The NAO robot is equipped with two video cameras that are mounted in the head of the robot. The first camera is installed in the middle forehead and the second one approximately 4 cm below. The lower camera is tilted by 39.7° with respect to the upper camera and both have a vertical opening angle of 43.7°. Because of that, the overlapping parts of the images are too small for stereo vision. It is also impossible to get images from both cameras at the exact same time, as they are not synchronized on a hardware level. This is why we analyze them separately and do not stitch them together. In order to be able to analyze the pictures of both cameras in real-time without losing any images, the cameras are handled in separate threads named Lower and Upper. They each run at 30 Hz.
During normal play, the lower camera sees only a very small portion of the field directly in front of the robot’s feet. Therefore, objects in the lower image are close to the robot and rather big. We take advantage of this fact and run the lower camera with half the resolution of the upper camera, thereby saving a lot of computation time. Hence, the upper camera provides 640 × 480 pixels while the lower camera only provides 320 × 240 pixels.
A major problem that can occur with NAOv6’s cameras are corrupted images. From experience, this mainly happens at the resolution we use for the lower camera and appears as fragmented camera images in which rows are not updated and occur repeatedly across multiple images. To counter this problem, a random image row is periodically selected for which the hash value is calculated in the following images. We monitor whether hash values occur repeatedly and reinitialize the cameras when this is the case.
Image Format and Color Spaces¶
Both cameras deliver their images in a YCbCr color space with chroma subsampling in a 4:2:2 format. That means, the horizontal chroma resolution is halved.
As is it often easier to code in terms of luma, hue and saturation, the YCbCr images are converted to the ECImage1 representation. The ECImage consists of multiple images: the grayscaled image obtained from the Y channel of the camera image, the saturated image and the hued image, containing saturation and hue values for each image pixel respectively.
The hue component H describes the angle of the vector of the Cb and Cr components of the color in the YCbCr color space. Meanwhile, the saturation component S describes the length of that vector divided by the luma of the corresponding pixel. The luma component Y is just the same as it is in YCbCr. By dividing the saturation by the luma, the resulting saturation value describes the actual saturation of the color more accurately, making it more useful for separating black and white from actual colors. This is because in YCbCr, the chroma components are somewhat dependent on the luminance.
Camera Matrix¶
The CameraMatrix is a representation containing the transformation matrix of the camera used in the respective thread that is provided by the CameraMatrixProvider. It is used for projecting objects onto the field as well as for the creation of the ImageCoordinateSystem. It is computed based on the TorsoMatrix that represents the orientation and position of a specific point within the robot’s torso relative to the ground. Using the RobotDimensions and the current joint angles, the transformation of the camera matrix relative to the torso matrix is computed as the RobotCameraMatrix. The latter is used to compute the BodyContour . In addition to the fixed parameters from the RobotDimensions, some robot-specific parameters from the CameraCalibration are integrated, which are necessary, because the camera cannot be mounted perfectly plain and the torso is not always perfectly vertical. A small variation in the camera’s orientation can lead to significant errors when projecting farther objects onto the field.
Extrinsic Camera Calibration¶
As each robot’s camera is attached with a slightly different rotation, we need to correct these rotations by applying a matching opposite rotation to the image. To find these values we perform the extrinsic camera calibration on each robot.
The process of manually calibrating the robot-specific correction parameters for the cameras is a very time-consuming task since the parameter space is quite large (8 parameters for calibrating both cameras) and it is not always obvious which parameters have to be adapted if a camera is miscalibrated. In particular during competitions, the robots’ cameras require recalibration often, e.g. after a robot returned from repair.
Therefore, we implemented an automatic calibration process. At the beginning of the calibration process, the robot needs to be placed at the sideline of a soccer field, facing the penalty cross. It will then walk to the correct positions for collecting samples of the goal area field lines and use them to optimize the rotation parameters. The details of the calibration mode are described in the Calibration section, in the following we describe the calibration algorithm.
 The image shows the upper camera view a robot has while collecting samples of the goal area lines.
The image shows the upper camera view a robot has while collecting samples of the goal area lines.
Automatic Camera Calibrator¶
The AutomaticCameraCalibrator performs the optimization of the camera parameters based on samples composed of lines of the goal area. It uses the Gauss-Newton algorithm to optimize the camera parameters. The error function used in the Gauss-Newton algorithm projects the components of the samples to field coordinates and compares the distances and angles between those with the known optimal ones. The different sample types used are the angle and distance between the ground line and the front goal area line and the angle between either of them and the short connecting line. While the AutomaticCameraCalibrator module could also take the distance from the penalty mark to the ground line and to the goal penalty area line into account, our calibration process currently collects no samples containing the penalty mark.
The information to construct the samples are gathered from the LinesPercept provided by the LinePerceptor and the PenaltyMarkPercept provided by the PenaltyMarkPerceptor.
The lines from the LinesPercept are not used directly because they do not describe the actual field lines accurately enough, i.e., they are not fitted. Instead, a hough transformation is performed to obtain a more accurate description of them. The start and end points of a line from the LinesPercept as well as its orientation are used to limit the considered angle range and the image area in which the hough transformation should be performed. The global maximum in the resulting hough space is used to calculate new start and end points. The remaining local maxima are used to determine whether the global maximum corresponds to the upper or lower edge of the line to take this into account by means of an offset when calculating the error.
A possible risk during sampling is that wrong lines are used to construct the samples, e.g. a detected line in the goal frame. This would lead to a corruption of the parameter optimization and result in an unusable calibration. In order to address this problem, an already almost perfect calibration is initially assumed and the lines are projected to field coordinates. In case the distances between the projected lines differ too much from the known actual distances, they are not used to construct samples but discarded. However, if lines are discarded continuously without being able to find suitable ones, the tolerated deviation is gradually increased, since it is known that the correct lines should be seen.
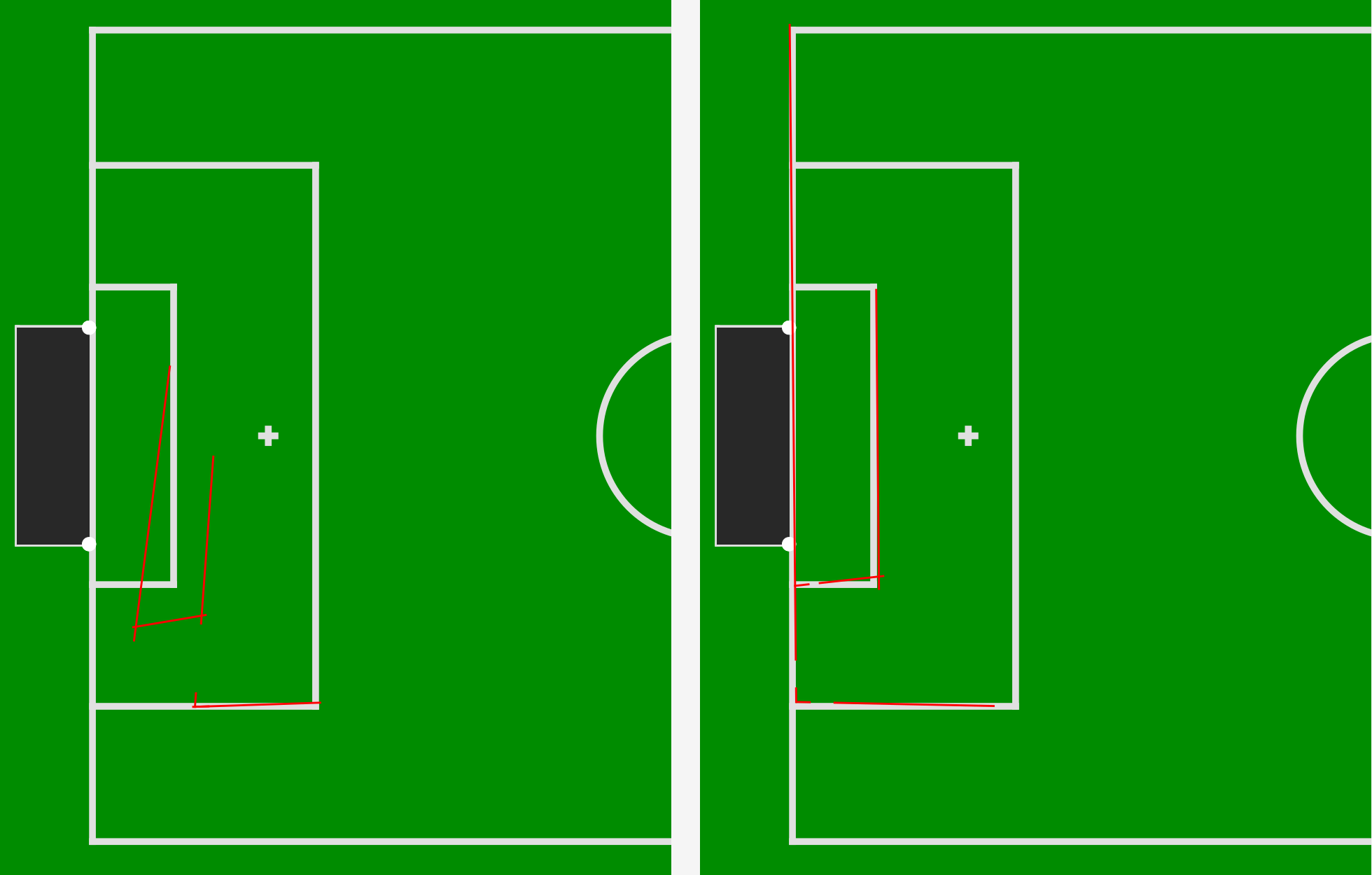 The image shows the projection of the perceived lines onto the field before and after calibration.
The image shows the projection of the perceived lines onto the field before and after calibration.
Controlling Camera Exposure¶
Under more natural lighting conditions, it is necessary to dynamically control the cameras’ exposures during the games. Otherwise, it might be impossible to detect features on the field if part of it is well lit while other parts are in the shadow. NAO’s cameras can determine the exposure automatically. However, normally they will use the whole image as input. At least for the upper camera, it can often happen that larger parts of the image are of no interest to the robot because they are outside the field. In general, the auto-exposure of the cameras cannot know what parts of the image are very important for a soccer-playing robot and which are less important. However, the cameras offer the possibility to convey such priorities by setting a weighting table that splits the image into four by four rectangular regions, as shown in the image.
Therefore, our code makes use of this feature. Regions that depict parts of the field that are further away than 3 m are ignored. Regions that overlap with the robot’s body are also ignored, because the body might be well lit while the region in front of it is in a shadow. If the ball is supposed to be in the image, the regions containing it are weighted in a way that they make up 50% of the overall weight. Changing the parameters of the camera takes time (mainly waiting). Therefore, the code communicating with the camera driver runs in a separate thread to avoid slowing down our main computations.


BodyContour¶
If the robot sees parts of its body, it might confuse white areas with field lines or other robots. However, by using forward kinematics, the robot can actually know where its body is visible in the camera image and exclude these areas from image processing. This is achieved by modeling the boundaries of body parts that are potentially visible 3-dimensionally (figure, left half) and projecting them back to the camera image (figure, right). The part of the projection that intersects with the camera image or above is provided in the representation BodyContour. It is used by image processing modules as lower clipping boundary. The projection relies on the representation ImageCoordinateSystem, i.e., the linear interpolation of the joint angles to match the time when the image was taken.

Field Boundary¶
Given that everything that is relevant to soccer playing robots is located on their field, it makes a lot of sense to limit image processing to the area of the field they are playing on or at least to reject object detections that do not overlap with that field. To be able to accomplish that, the field boundary in the current camera image must be detected.
Detecting the field boundary is one of the first steps in our vision pipeline. Conventional methods make use of a (possibly adaptive) green classifier, selection of boundary points and possibly model fitting. Our approach predicts the coordinates of the field boundary column-wise in the image using a convolutional neural network. This is combined with a method to let the network predict the uncertainty of its output, which allows to fit a line model in which columns are weighted according to the network’s confidence. Experiments show that the resulting models are accurate enough in different lighting conditions as well as real-time capable. The figure shows the detected field boundaries and the predicted uncertainty. For a detailed explanation see 2

Sample images with the output of the network with uncertainty. The solid red line is the predicted mean, the dotted lines are ±σ intervals, and the blue line is the fitted model.
-
ECImagestood for “extracted and color-classified image”. In earlier version it also contained a fourth image with each pixel classified into one of four color classes. As this relied on manual color calibration, it was removed, the representation's name stayed though. It might be due to be renamed. ↩ -
Arne Hasselbring and Andreas Baude: "Soccer Field Boundary Detection Using Convolutional Neural Networks". In: Rachid Alami, Joydeep Biswas, Maya Cakmak, Oliver Obst (eds) RoboCup 2021: Robot World Cup XXIV. RoboCup 2021. Lecture Notes in Computer Science(), vol 13132. Springer, Cham. https://doi.org/10.1007/978-3-030-98682-7_17 ↩