Localizations Features¶
Self-Localization of the robots relies mainly on features detected through image recognition. That includes the field lines, the center circle and the penalty marks. The detection modules of all three use a shared pre-processing step. It provides a grid of scan lines divided into regions that show the field, something white, or something else. There, the image processing flow splits into modules for detecting the specific features. Then the detected lines, center circle and penalty mark are also merged again into composite localization features, such as line intersections, center circle with center line and penalty mark with penalty area.
Scan Grid / Scan Line Regions¶
As a pre-processing step we scan in image in horizontal and vertical lines, that are close enough together to find field lines, penalty marks and the ball. Therefore, we compute the ScanGrid dynamically depending on the vertical orientation of the camera. The distance between to grid points roughly corresponds to a distance of a bit less than the expected width of a field line at that position in the image. The resulting grid can be seen in the left half of the following image.
Then, the scans are executed by the ScanLineRegionizer module, which provides the vertical and horizontal scan line regions shown in the middle and on the right side. It divides the scan lines into regions and classifies them as either field, white or a generic class none that stands for everything else. Regions classified as white are shown in red for better visibility.
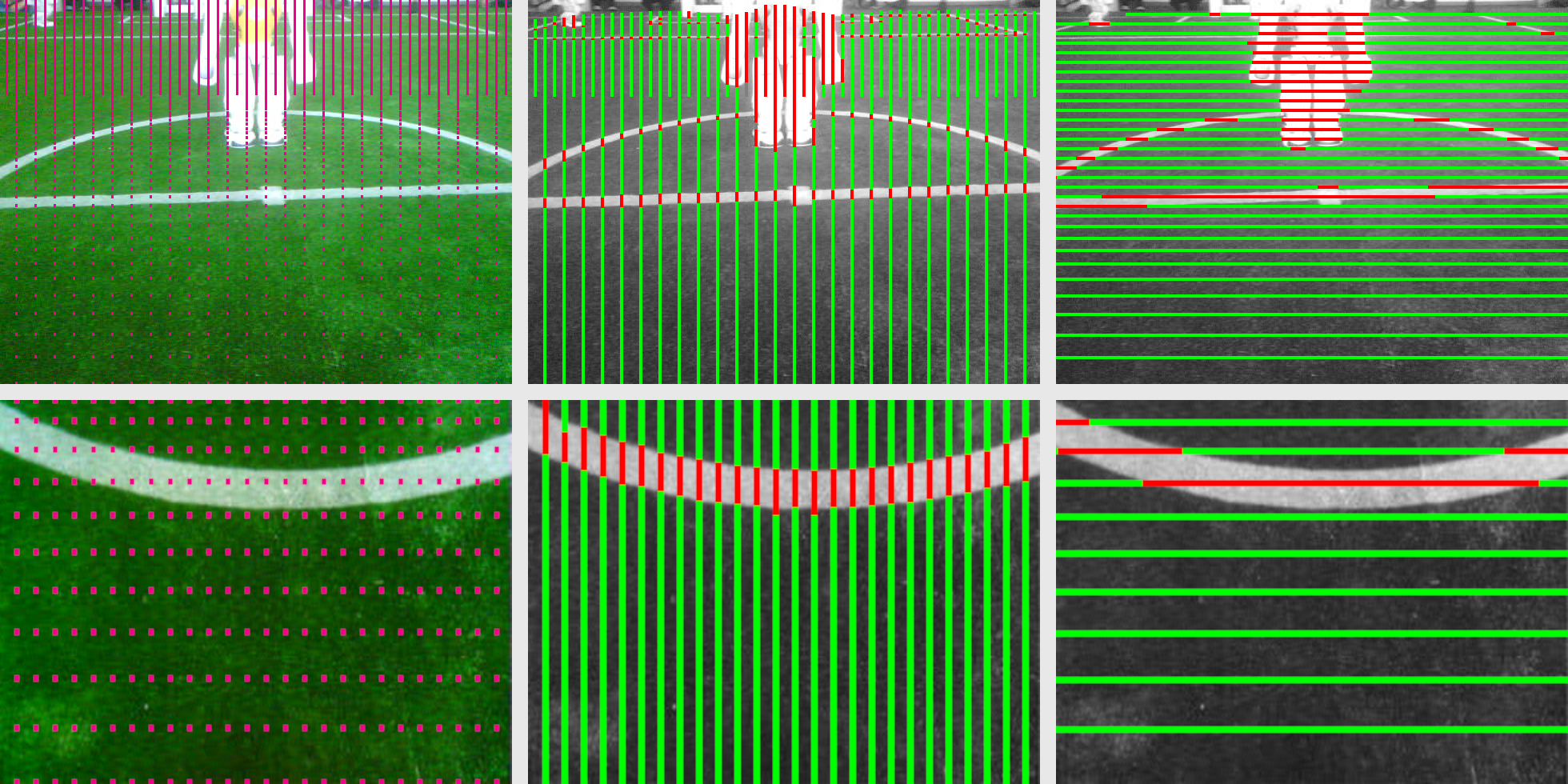
The scan line regions are generated without prior color calibration. In order to obtain reliable results even under dynamic lighting conditions, the color ranges initially assigned to the various color classes are recalculated for each image. For the determination of the beginning and end of the regions, no fixed color ranges are used at all but only local comparison points. The steps in detail are as follows:
- Define the scan lines
- Limit the range of the scan lines to exclude parts outside the field boundary and where the robot sees itself.
- Detect edges and create temporary regions in between
- Compare luminance between neighboring grid points. If the difference is above a threshold, find the position with the highest luminance change in between.
- Assign a YHS triple to each region, that represents its color.
- Classify field regions
- Unite all neighboring regions of similar colors that are in the possible field color range in union-find-trees.
- Classify all union-regions that span enough pixels as field and determine the field color range.
- Classify the remaining regions that match the field color range as field.
- Classify white regions
- All regions significantly brighter than both neighboring regions.
- Infer white color range from field color range and approximated image average luminance and saturation.
- All regions that were not previously labeled as field and match the white color range.
- Fill small gaps between field and white regions
- Sometimes small regions that lie between field and white cannot be classified with certainty. They become split in the middle.
- Merge neighboring regions of the same class
The horizontal and vertical scan lines are currently calculated independently and don't become synchronized. Therefore, a grid point classified as one class in the horizontal scan lines might be classified differently in the vertical scan lines.
Field Line Detection¶
Line Spots¶
The perception of field lines and the center circle by the LinePerceptor rely on the scanline regions. In order to find horizontal lines in the image, adjacent white vertical regions that are not within a perceived obstacle are combined to line segments (shown in blue). Correspondingly, vertical line segments are constructed from white horizontal regions (shown in red). These line segments and the center points of their regions, called line spots, are then projected onto the field.

Detecting Lines¶
Using linear regression of the line spots, they are then merged together and extended to larger line segments. During this step, line segments are only merged together if they pass a white test. For this we sample points close but definitely outside the presumed line in a regular interval to both sides of the checked line segments. A given ratio of the checked points need to be less bright and more saturated than their corresponding point on the presumed line segment. Only then the line spots are merged to a segment, otherwise the presumed segment get rejected. The left image shows this process, with accepted line segments in blue, rejected segments in red and the checked points in orange. The right image shows the eventually found line percepts.

Detecting the Center Circle¶
Besides providing the LinesPercept containing perceived field lines, the LinePerceptor also detects the center circle in an image if it is present. In order to do so, when combining line spots to line segments, their field coordinates are also fitted to circle candidates. After the LinesPercept was computed, spots on the circle candidates are then projected back into the image and adjusted so they lie in the middle of white regions in the image. These adjusted spots are then again projected onto the field and it is once again tried to fit a circle through them, excluding outliers.
If searching for the center circle using this approach did not yield any results, another method of finding the center circle is applied. We take all previously detected lines whose spots describe an arc and accumulate the center points of said arcs to cluster them together. If one of these clusters contains a sufficient number of center points, the average of them is considered to be the center of the center circle.
If a potential center circle was found by any of these two methods, it is accepted as a valid center circle only if – after projecting spots on the circle back into the image – at least a certain ratio of the corresponding pixels is white, using the same whiteness test as in the line detection.
The image shows the detected inner and outer edge of the circle used for finding the circle center point. The right side shows the filtered line and circle percepts in the FieldLines representation.

Line Intersections¶
Part of the self-localization is the usage of line intersections as landmarks. Not only is the position of an intersection important but also the type of intersection. Previously, we determined the location and type of the intersections by calculating where perceived field lines coincide. This method proved to be very reliable regarding the detection of intersections. The classification however only provides reliable results for intersections that are not beyond 3 m. Because of this, we implemented a convolutional neural network that classifies all intersections. Using both classification approaches and depending on the output of the CNN either the classification result of the CNN or geometric approach will be used.
Both classification approaches work on candidates, i.e. two lines that possibly intersect. To generate candidates, each previously detected line will be compared to all other detected lines, excluding those that are known to be part of the center circle. Because of the way the field is set up an intersection is only possible if the inclination of two compared lines in field coordinates is roughly 90°. The candidates for the classification are generated in the IntersectionsCandidatesProvider module and classified by the IntersectionsClassifiermodule.
We divide the intersections into three types, which we call L, T, and X, corresponding to the shape formed by the lines on the field. The IntersectionsPercept representation then stores the type of each intersection as well as its position, its basis lines, and its rotation.
Geometric Approach¶
For each candidate, the point of intersection of the two lines is calculated. In order to be valid, this point must lie in between both detected line segments. The classification of intersection types uses the endpoints of the involved lines. This means that intersections lying clearly in-between both lines are of type X while those that are clearly inside one line but roughly at one end of the other are considered to be of type T. If the point of intersection lies roughly at the ends of both lines, it is assumed to belong to an L-type intersection.
In case that parts of both lines are seen but the point of intersection does not lie on either line - e.g. because an obstacle is standing in front of the intersection point – the lines will be virtually stretched to some extent so that the point of intersection lies roughly at their ends. The possible distance by which a line can be extended depends on the length of its recognized part.
CNN Approach¶
For the CNN a candidate consists of a 32 × 32 pixels grayscale image of the intersection and the distance to the robot. Both will be input into the neural network, where it will be classified. By also inputting the distance between the robot and intersection, we add more context to the image for the network. The network has four output classes: L, T, X and NONE. The first three classes represent the three different intersection types on the field. A candidate will be classified as NONE, if no intersection can be seen on the image. If the output probability distribution of the network has no clear classification result, the estimated line type from the geometric approach is used.
Close to 12000 images were used to train the model. These images were extracted from logs of B-Human games from the last years under different lighting conditions.
Goal Post Detection¶
Within the penalty area, the goal posts are another type of field features that can be used in the self-localization. Especially in game situations in which players are inside the penalty area, the goal posts can be valuable landmarks on the field. The GoalPostsPerceptor is a module that uses the camera images of the NAO to detect the base point of goal posts.

The goal post base is marked with a red X in the image above.
Approach¶
To achieve the detection of goal posts, candidate regions are generated that contain possible goal posts. To verify whether a goal post is actually inside one of these regions a Convolutional Neural Network (CNN) is used to classify the candidates into two classes: "Goal Post" and "No Goal Post". If it was determined that a goal post is inside this candidate, another CNN is used to predict the coordinates of the goal post's base point. This base point is then used for further calculations in the self-localization.
Finding Candidate Regions¶
The process to generate candidates of possible goal posts is divided into four steps. These steps are the same for the upper and lower camera of the NAO.
Scan Line Regions¶
All goal posts on a RoboCup SPL field are white. Which is why the first step consists of finding all white objects in the camera image using horizontal white scan line regions. These scan line regions are then filtered to remove unwanted candidates. Scan Line Regions that are on top recognized FieldLines and at a distance of 2.5 m to the robot are removed from the candidate pool.

This image shows the horizontal white scan line regions on top of a goal post.
Expanding Regions¶
In order to capture the whole goal post, the scan line regions are expanded in every direction, forming a rectangle around the goal post captured by scan line regions.
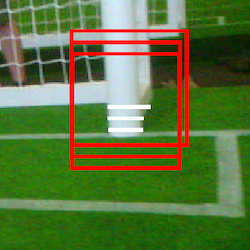
The expanded rectangles that are formed by expanding the scan line regions can be seen in red.
Combining Overlapping Regions¶
By expanding every white scan line region into a rectangle, overlap between rectangles of neighboring scan line regions is occurring. In order fix this issue, all the candidate regions with a certain overlap percentage are combined into one rectangle.
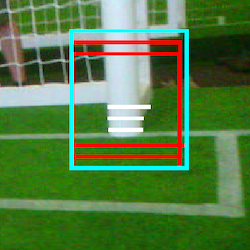
The combination of all overlapping candidate regions is depicted in cyan.
Forming the Goal Post Candidate¶
The last step of the candidate generation consists of turning the rectangular goal post candidates into images that can be used as input for the CNNs. Firstly, the rectangles are transformed into squares by cutting off the excess upper portion of the candidate region. Then the square candidate is scaled up or down to 32 x 32 pixels. The result is a grayscale camera image of the shape (32 x 32 x 1).
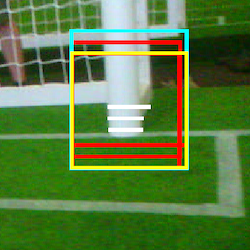
In this image, the final patch of the goal post candidate can be seen in yellow.
Data Collection¶
In the training process of both CNNs a total of 8200 grayscale images of the shape (32 x 32 x 1) were used. An example of such an image can be seen in the following figure.

These images were extracted from B-Human logs of games during the RoboCup 2022, GORE 2023, and RoboCup 2023 using the candidate generation described in the previous section. Special attention was paid to ensure that a wide variety of lighting conditions and field locations are represented in the data set. 25.8% of the data set are images of goal posts. The rest were false positives provided by the candidate generation.
Classification¶
To classify the candidates into the two classes "Goal Post" and "No Goal Post" the following CNN architecture was used.
| Layer Type | Output Size | Number of Parameters |
|---|---|---|
| Input | 32 × 32 × 1 | |
| Convolutional | 30 × 30 × 8 | 72 |
| Batch Normalization | 30 × 30 × 8 | 24 |
| ReLU | 30 × 30 × 8 | 0 |
| Max Pooling | 15 × 15 × 8 | 0 |
| Convolutional | 13 × 13 × 8 | 576 |
| Batch Normalization | 13 × 13 × 8 | 24 |
| ReLU | 13 × 13 × 8 | 0 |
| Max Pooling | 6 × 6 × 8 | 0 |
| Convolutional | 4 × 4 × 16 | 1152 |
| Batch Normalization | 4 × 4 × 16 | 48 |
| ReLU | 4 × 4 × 16 | 0 |
| Max Pooling | 2 x 2 x 16 | 0 |
| Convolutional | 2 x 2 x 16 | 2304 |
| Batch Normalization | 2 x 2 x 16 | 48 |
| ReLU | 2 x 2 x 16 | 0 |
| Max Pooling | 1 × 1 × 16 | 0 |
| Flatten | 16 | 0 |
| Dense + ReLU | 16 | 272 |
| Dense + Sigmoid | 1 | 17 |
Detection¶
To predict the image coordinates of the goal post's base point a CNN with the following architecture was used.
| Layer Type | Output Size | Number of Parameters |
|---|---|---|
| Input | 32 × 32 × 1 | |
| Convolutional | 30 × 30 × 8 | 72 |
| Batch Normalization | 30 × 30 × 8 | 24 |
| ReLU | 30 × 30 × 8 | 0 |
| Max Pooling | 15 × 15 × 8 | 0 |
| Convolutional | 13 × 13 × 8 | 576 |
| Batch Normalization | 13 × 13 × 8 | 24 |
| ReLU | 13 × 13 × 8 | 0 |
| Max Pooling | 6 × 6 × 8 | 0 |
| Convolutional | 4 × 4 × 16 | 1152 |
| Batch Normalization | 4 × 4 × 16 | 48 |
| ReLU | 4 × 4 × 16 | 0 |
| Max Pooling | 2 x 2 x 16 | 0 |
| Convolutional | 2 x 2 x 16 | 2304 |
| Batch Normalization | 2 x 2 x 16 | 48 |
| ReLU | 2 x 2 x 16 | 0 |
| Flatten | 64 | 0 |
| Dense + ReLU | 16 | 1040 |
| Dense + ReLU | 2 | 34 |
While the whole data set of 8200 images was used to train the binary classifier. Only the 2115 images that contain actual goal posts were used to train the detector.
Penalty Mark Perception¶
The penalty mark is one of the most prominent features on the field since it only exists twice. In addition, it is located in front of the penalty area and can thereby be easily seen by the goal keeper. By eliminating false positive detections, the penalty mark can be used as a reliable feature for self-localization. This is achieved by limiting the detection distance to 3 m and by using a convolutional neural network for classification of candidates.
Approach¶
Similar to the ball detection, the image is first searched for a number of candidates which are checked afterward for being the actual penalty mark. The search for candidates and the actual check are separated into different modules. This allows us to handle the generation of candidate regions differently depending on the camera, while the verification is the same in both cases.
Finding Candidate Regions¶
Upper Camera¶
For images from the upper camera the PenaltyMarkRegionsProvider generates the penalty mark candidates. First, it collects all regions of the scanned low resolution grid that were not classified as green, i.e. white, black, and unclassified regions. In addition, the regions are limited to a distance of 3 m from the robot, assuming they represent features on the field plane. Vertically neighboring regions are merged and the amount of pixels that were actually classified as white in each merged region is collected. Regions at the lower end and the upper end of the scanned area are marked as invalid, i.e. there should be a field colored region below and above each valid region. The regions are horizontally grouped using the Union Find approach. To achieve a better connectedness of, e.g., diagonal lines, each region is virtually extended by the expected height of three field line widths when checking for the neighborhood between regions. For each group, the bounding box and the ratio between white and non-green pixels is determined. For all groups with a size similar to the expected size of a penalty mark that are sufficiently white and that do not contain invalid regions, a search area for the center of the penalty mark and a search area for the outline of the penalty mark are computed. As the search will take place on 16 × 16 cells, the dimensions are extended to multiples of 16 pixels.

Lower Camera¶
For lower camera images, we use a CNN on the full image for candidate generation. Running the network on the full image in real time is possible only because we use the lower camera at lower resolution, so this is not a viable approach for the upper camera. The network acts as a multi-perceptor, detecting balls, robots and penalty marks at the same time. Only the penalty mark prediction with the highest confidence becomes a candidate to be double-checked.
Checking Penalty Mark Candidates¶
The candidates are classified together with the ball candidates using a single convolutional neural network (see this section).